语音转口型
前言
之前做GPT聊天时,用Live2D的简单的通过音量大小来驱动嘴型的大小变化,这里想更精确一定,用元音来驱动。
主要就是复刻了这位大佬的这篇文章。
大致思路
初看时被一堆术语吓到了,什么频域信息、窗函数、高斯滤波器、DCT变换、共振峰等等。
耐心一点一点看就发现还是比较简单的,很多算法并不一定要从新造轮子去实现,知道其目的就好了。
获取语音数据的频域信息
这里直接用AudioSource.GetSpecturmData即可。这里其实就包含了之前提到的频域信息和窗函数。

高斯滤波
就像通常的高斯模糊的卷积一样,这里也可以在一维空间高斯滤波一次,去除噪音。
提取共振峰
简单说就是寻找局部最大值的最大值所在的频率位置。
这个位置就是用来判定元音的依据了。
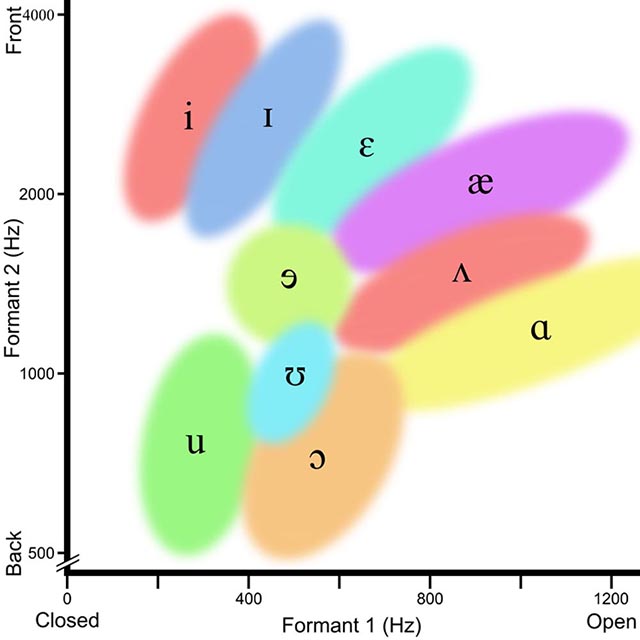
注意的是,原文给出的5个元音的判断的频率,仅仅针对采样率为44Khz的文件,其他采样率要自行修改。
结合Live2D
live2d有自己的一套奇奇怪怪的框架去修改参数,还要考虑排序。
好在其插件基本开源,参照着写就行了,根据当前的元音去混合口型动画。
总结

放在Live2D上效果确实比之前单纯的用音量来控制好的多,但也仅限于是增加了口型的多样性,很难说是“正确”的口型。
这里最主要的原因在于
- 不同人声的各个元音的共振峰并不相同,需要根据配音来调整
- 只考虑了第一共振峰,误差太大,可以参照下表结合第二共振峰去判断,效果应该更好。
语音转口型
https://www.kuanmi.top/2023/02/08/lip/